Высоконагруженная система управления инцидентами в банке

TNB технологии
Development
min read
Банковская отрасль — одна из наиболее требовательных сфер к надёжности и устойчивости информационных систем. Каждая секунда простоя, вызванная упавшим сервером или недоступным API, способна обернуться потерями в финансовых показателях и репутации. Именно поэтому вопрос создания и поддержания системы управления инцидентами становится для банка приоритетным.
Предпосылки для разработки платформы
Крупная банковская организация столкнулась с набором классических, но критичных проблем в управлении инцидентами:
Отсутствие единой точки управления: информация о сбоях и простоях стекалась из множества разрозненных мониторинговых систем. При этом не было централизованного места, где можно было бы увидеть все данные в реальном времени.
Задержка в реакции: сотрудников уведомляли о сбое с опозданием или по нескольким каналам одновременно, без чёткого приоритета и распределения ролей.
Сложная координация: при появлении инцидента сразу вовлекались несколько команд (департамент DevOps, служба IT-безопасности, отдел инфраструктуры), но без налаженных сквозных процессов координация затягивалась и приводила к пересекающимся действиям.
Чтобы решить эти проблемы и улучшить время восстановления (MTTR, Mean Time to Recovery), банк инициировал проект по созданию распределённой системы, способной мониторить критические сервисы в режиме реального времени и структурировать все инциденты в унифицированном интерфейсе.
Ключевые требования
Высокая пропускная способность: система должна обрабатывать тысячи событий в секунду, поступающих из множества источников (лог-сервера, сети, веб-сервисы, платёжные шлюзы и пр.).
Надёжность и отказоустойчивость: любые сбои в самой платформе недопустимы, так как это сводит на нет весь смысл системы, призванной контролировать инциденты.
Безопасность: банк оперирует конфиденциальными данными клиентов, и любая утечка или несанкционированный доступ чреваты серьёзными последствиями (штрафы, падение доверия, имиджевые потери).
Удобный интерфейс для различных ролей: оператор мониторинга и технические специалисты должны иметь разные уровни доступа и набор инструментов, что упрощает командную работу и ускоряет принятие решений.
Архитектура и реализация
Проект был построен на основе микросервисного подхода, что позволило добиться гибкой масштабируемости и распределённой обработки данных. Каждая функциональная область (мониторинг, уведомления, корреляция событий, аналитика) развёртывается как независимый сервис со своим API. Благодаря этому, любая часть системы может обновляться и масштабироваться отдельно от других, что снижает вероятность «точек отказа».
Сбор событий: на нижнем уровне функционируют агенты, установленные на серверах и сервисах банка, которые отслеживают логи и системные метрики (CPU, память, сетевой трафик) и пересылают их в центральный брокер сообщений.
Обработка и корреляция: после поступления в брокер, данные распределяются по соответствующим микросервисам. Специализированные алгоритмы (в том числе на базе ML) анализируют логи, сопоставляют текущие метрики с историческими и определяют потенциальные инциденты или аномалии.
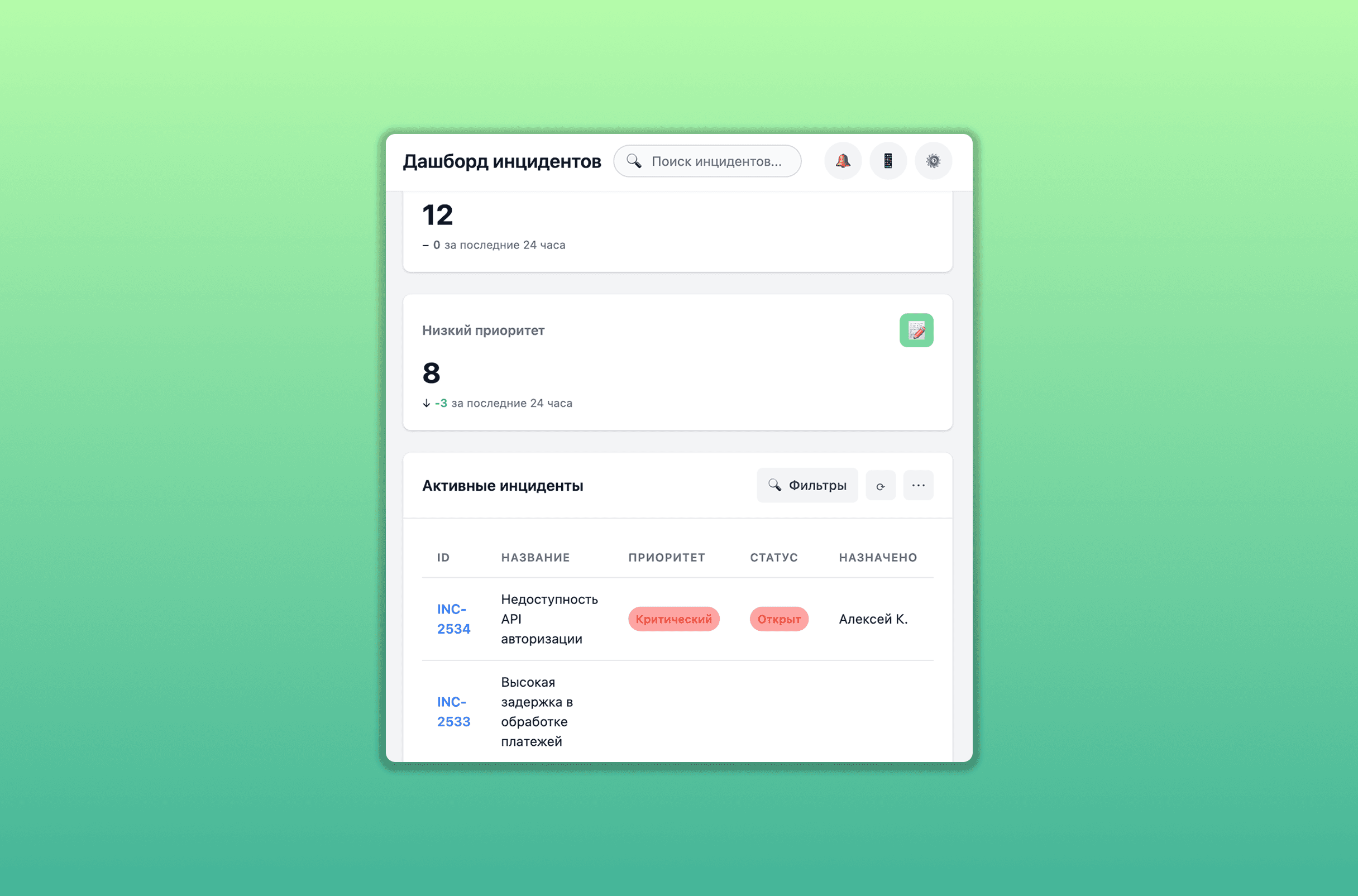
Управление инцидентами: при обнаружении сбоя автоматически создаётся «карточка» инцидента, где указываются приоритет, статус, ответственные команды и т.д. Дальнейшие действия пользователей фиксируются, создаётся история переписки и изменений.
Уведомления и эскалация: система интегрирована со всеми корпоративными мессенджерами и системой электронной почты. При срабатывании триггера уведомление направляется ответственным, причём формат и канал уведомлений варьируются в зависимости от критичности инцидента (SMS, Push, e-mail, корпоративный мессенджер).
Отчёты и аналитика: для управленцев высшего звена и руководителей отделов предусмотрены визуальные дашборды, отражающие ключевые метрики — время простоя сервисов, процент успешных транзакций, средний срок решения инцидентов и т.д.
Безопасность и распределение нагрузки
Система была развёрнута в нескольких географических локациях банка с резервированием основных компонентов. Если одна дата-центрная площадка выходит из строя, другая автоматически подхватывает трафик и продолжает работу без заметных простоев. Данные хранятся в зашифрованном виде, а доступ к системе регулируется многофакторной аутентификацией и ролевой моделью.
Результаты и эффекты
Сокращение MTTR на 40%: время на обнаружение и устранение инцидента снизилось, поскольку ответственным сотрудникам достаточно просмотреть единый интерфейс и получить инструкции к действию.
Рост прозрачности процессов: благодаря системе учёта и логирования, управленцы видят, как распределяются ресурсы и кто отвечает за какие задачи.
Сокращение повторяющихся проблем: инструменты корреляции позволяют выявить паттерны и устранять корневые причины проблем, а не только их симптомы.
Эффективное планирование нагрузки: благодаря аналитике загруженности сервисов, банк может заранее масштабировать критические системы перед пиковыми периодами (например, в отчётные даты или во время массового использования платёжных инструментов).
Стратегические выгоды для банка
Укрепление доверия клиентов: бесперебойность сервисов — ключевой фактор при выборе банка, ведь даже кратковременная недоступность мобильного или интернет-банка может привести к оттоку пользователей.
Сокращение финансовых потерь: каждый инцидент теперь устраняется быстрее, а значит снижаются риски, связанные с просрочкой платежей или недоступностью транзакций.
Улучшение репутации среди партнёров: наличие прозрачного механизма решения проблем повышает ценность банка в глазах контрагентов и регулирующих органов.
Таким образом, созданная высоконагруженная распределённая система управления инцидентами успешно закрыла задачу по мониторингу критичных сервисов и оперативному реагированию на сбои. Проект продемонстрировал, что комплексный подход к разработке, внедрению и обучению персонала позволяет достичь существенных результатов не только в снижении простоя, но и в общем повышении зрелости IT-инфраструктуры.